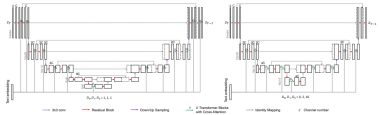
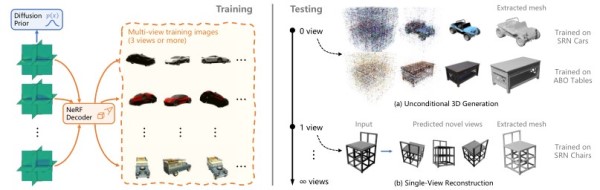
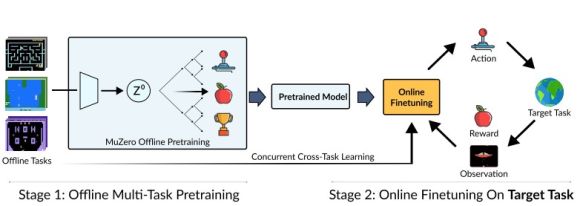
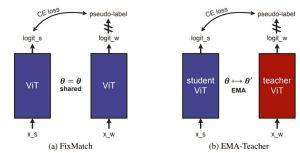
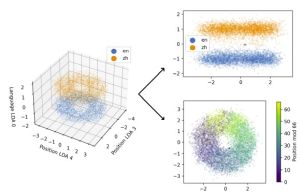
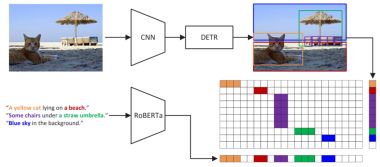
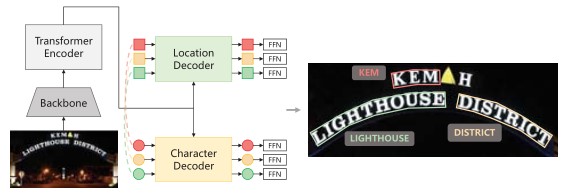
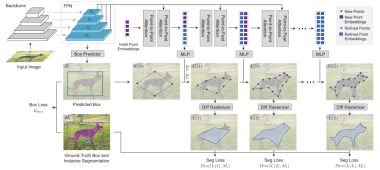
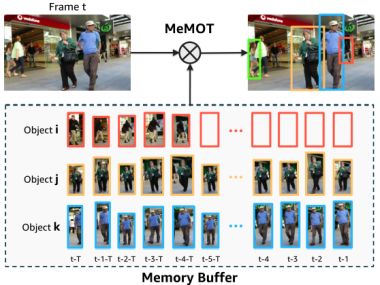
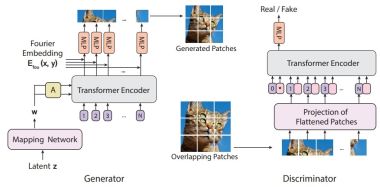
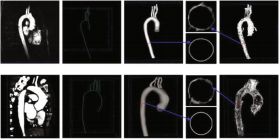
PixARMesh: Autoregressive Mesh-Native Single-View Scene Reconstruction
Xiang Zhang, Sohyun Yoo, Hongrui Wu, Chuan Li, Jianwen Xie, and Zhuowen Tu
CVPR 2026 / Paper / Project Page

Talk2Move: Reinforcement Learning for Text-Instructed Object-Level Geometric Transformation in Scenes
Jing Tan, Zhaoyang Zhang, Yantao Shen, Jiarui Cai, Shuo Yang, Jiajun Wu, Wei Xia, Zhuowen Tu, and Stefano Soatto
CVPR 2026 / Paper / Project Page
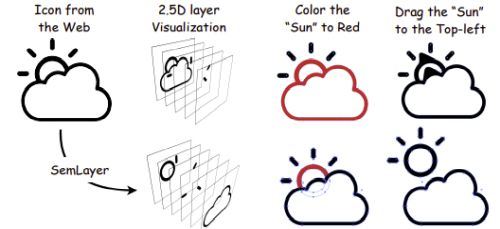
SemLayer: Semantic Generative Segmentation and Layer Reconstruction for Vector Icons
Haiyang Xu, Ronghuan Wu, Li-Yi Wei, Nanxuan Zhao, Chenxi Liu, Cuong Nguyen, Zhuowen Tu, and Zhaowen Wang
CVPR 2026 / Paper / Project Page
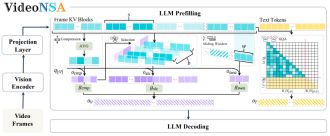
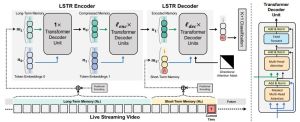
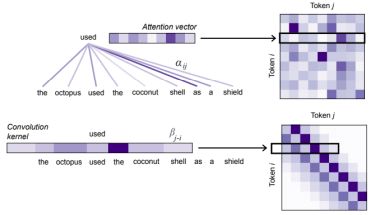
VideoNSA: Native Sparse Attention Scales Video Understanding
Enxin Song, Wenhao Chai, Shusheng Yang, Ethan J. Armand, Xiaojun Shan, Haiyang Xu, Jianwen Xie, and Zhuowen Tu
ICLR 2026 / Paper / Project Page
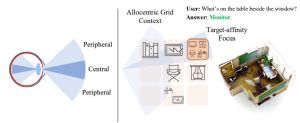
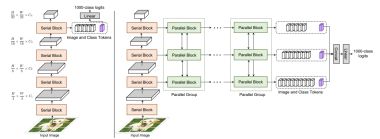
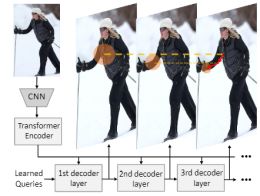
CVP: Central-Peripheral Vision-Inspired Multimodal Model for Spatial Reasoning
Zeyuan Chen, Xiang Zhang, Haiyang Xu, Jianwen Xie, and Zhuowen Tu
WACV 2026 / Paper

OverLayBench: A Benchmark for Layout-to-Image Generation with Dense Overlaps
Bingnan_Li, Chen-Yu Wang, Haiyang Xu, Xiang Zhang, Ethan J. Armand, Divyansh Srivastava, Xiaojun Shan, Zeyuan Chen, Jianwen Xie, and Zhuowen Tu
NeurIPS 2025 (Datasets and Benchmarks Track) / Paper

YOLO-Count: Differentiable Object Counting for Text-to-Image Generation
Guanning Zeng, Xiang Zhang, Zirui Wang, Haiyang Xu, Zeyuan Chen, Bingnan Li, and Zhuowen Tu
ICCV 2025 / Paper

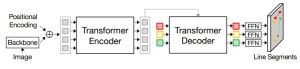
DepR: Depth Guided Single-view Scene Reconstruction with Instance-level Diffusion
Qingcheng Zhao, Xiang Zhang, Haiyang Xu, Zeyuan Chen, Jianwen Xie, Yuan Gao, and Zhuowen Tu
ICCV 2025 / Paper

Lay-Your-Scene: Natural Scene Layout Generation with Diffusion Transformers
Authors: Divyansh Srivastava, Xiang Zhang, He Wen, Chenru Wen, and Zhuowen Tu
ICCV 2025 / Paper

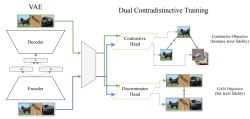
Salient Concept-Aware Generative Data Augmentation
Tianchen Zhao, Xuanbai Chen, Zhihua Li, Jun Fang, Dongsheng An, Xiang Xu, Zhuowen Tu, and Yifan Xing
NeurIPS 2025 / Paper

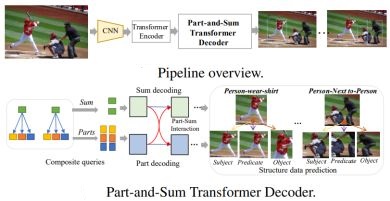
Ground-V: Teaching VLMs to Ground Complex Instructions in Pixels
Yongshuo Zong, Qin Zhang, Dongsheng An, Zhihua Li, Xiang Xu, Linghan Xu, Zhuowen Tu, Yifan Xing, and Onkar Dabeer
CVPR 2025 / Paper